SCM Patterns for versioning services


One thing that I find remarkable about current IT Industry best practices is that we daily use the closest thing we have available to a Time Machine. If this was more widely known to students, Computer Science education might appear even more cutting edge than it now is (and "Great Scott!", it could even impress Dr. Emmett Brown, .... maybe 😉).
However, Source Code Management (SCM) practices are not a big part of academic curricula, since are more in support of collaborative development rather than individual skills that are key to achieving an educational degree for the individual.
But as soon as we are involved in large-scale projects (and Business Platforms based on Cloud and Microservices definitely qualify), these became central in everyday work.
In this post, I will have a look at key concepts that are at the base of these tools, and at effective usage patterns applicable to service platform development.
How SCM Tools support collaboration
Collaboration support is provided by helping to manage file changes through time, with features that have evolved through time with the newer generation tools.
Early tools, such as Revision Control System(RCS), focused on versioning the history of individual files and providing collaboration features such as Locks focused on preventing conflicts due to concurrent modifications of the same file. This approach (akin to DB Pessimistic locking), while guaranteeing consistency, limits efficiencies due to parallel development.
Subsequent generation tools, such as Concurrent Versions System (CVS), focused on allowing concurrent development, enabling a development process that forces conflict resolution before committing (akin to DB Optimistic locking), and storing the changes in the history repository. CVS did become hugely popular and used for enabling collaboration on OpenSource projects, especially through SourceForge.
However, large projects require tracking time and version dependencies between multiple files. Even if CVS provided features to commit multiple files at the same time, these were limited and not too consistent (e.g. lacking atomicity, and no folder versioning support). Apache Subversion (SVN) was the next step of evolution and provided an atomic changeset of multiple files and folders, creating a consistent history graph of entire projects and not only of single files, with even better capabilities of moving consistently through code versions along the timeline.
Modern tools provide additional features, such as:
- distributed repositories (Git, Mercurial) that allow working offline and scaling to thousands of users.
- cheaper and more manageable branching, that allows committing individual changes before merging across different branches (Rational Team Concert, Git, Mercurial), making development safer by saving and backing up work at any time
Currently, Git-based solutions, especially GitHub, are extremely popular and easily available online.
However these are just tools, let's have a look at some common collaboration patterns, in order to choose the most effective strategy for our projects.
GitFlow Usage pattern
This pattern is close to the Linux kernel source configuration processes. It's essentially based on a hierarchical communication structure, where developer branches are handled by key lead developers that integrates code developed by teams on different feature branches.
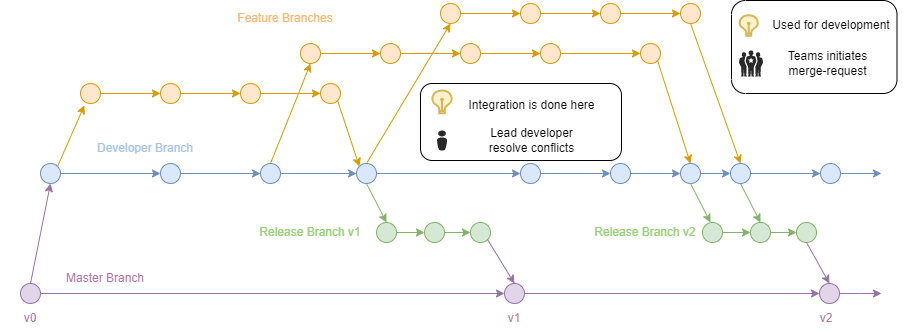
Key aspects of this model:
- Concentrate responsibilities on the Lead developer controlling the development branch, ensuring review of all work
- All development work is reviewed before integration, reducing the trust required from other contributors
- Contributions are merged into the development branch asynchronously, favoring distributed work between multiple persons at different times
On the flip side:
- A complex process, with constant merge requests to be managed, that slows down the development pace
- Long time spent in Feature branches makes merging and integration complex, with many potential reworks
- The lead developer integration role is central, leading to significant risks in case of unavailability
Trunk-based-development Usage pattern
This approach assumes a completely opposite communication structure, based on a small group of closely collaborating peers like usually found on Agile projects. Code ownership is shared and changes are continuously integrated into the Trank branch. Work on individual features might happen in specific branches, but these are short-lived and integration responsibility remains on the specific person handling the branch.
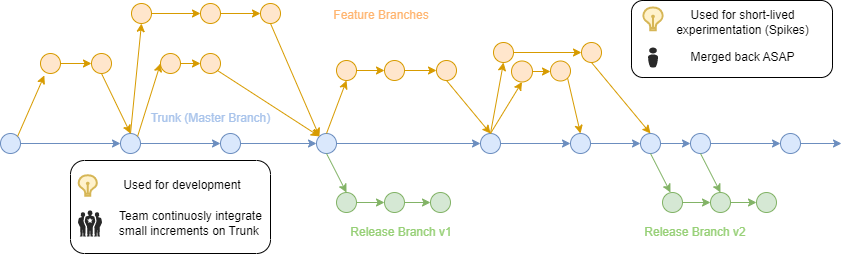
Key aspects of this model:
- A Simpler, less formal process, that allows much greater delivery speed.
- Greater delivery speed and short-lived feature branches enable a continuous delivery process, that reduces integration risks.
- Not relying on a central authority figure to resolve conflicts
On the flip side:
- Requires trust and accountability of all participants. While often this is associated with developer seniority, with the right people mix it becomes a powerful motivator for up-skilling junior people and making them accountable (e.g. with Agile techniques such as Pair Programming )
- Not safely applicable to scenarios with many "untrusted" contributors working asynchronously
Selection Criteria
While different SCM tools have specific features that support either style, the real selection criteria depend on the context of the specific project, based on required communication patterns.
Open Source projects and commercial product development usually benefit more from a GitFlow approach because of:
- the larger number of involved "untrusted" developers (either Open Source contributors or Support people producing bug fixes) that require a formal change approval process. E.g. merge-request approval by an OSS project maintainer. Each request could come from unknown contributors.
- relative infrequent scheduled releases, that allow periodic integration cycles
Most software development projects on clients, often executed with Agile methods benefit more from a Trunk-based-development approach because of:
- a relatively small team, fully committed to the specific engagement.
- very fast incremental release schedule, using a continuous delivery approach
Conclusion
In the end, the best strategy for a specific context will combine these two approaches. For example, a Business Platform will be developed with an Agile approach, but the release branches will need more formal hierarchical approvals to ensure the segregation of responsibilities.
Cloud-native development with Microservices, given the small team sizes, incremental agile delivery, and speed of release is a good fit for starting with Trunk-based-development.