Evolving Domain Model Entities


Successful business platforms and architectures need to handle change and evolution gracefully. A good problem domain decomposition, documentation, and versioning of Business API and Entities, ideally using Domain-Driven-Design (DDD) principles, help evolve the functional side.
But there is an additional need. The choice of the Database platform and how to use it will impose operational constraints on evolution options and costs.
Handling effectively the evolution of Persistent Data is a crucial aspect, especially when there is a need to keep data records available for a long time. A flexible and cost-effective solution is required for evolving in an Agile and incremental way the persistent data together with the Domain Model updates.
In this post I will touch on an approach I used on very large-scale engagement:
- Choosing a persistency Strategy
- Versioning the persisted entities
- Evolving the entities
- Key Highlights
Choosing a persistency Strategy: is Relational vs Object the issue?
For this approach, the choice between Relation vs Object (or SQL vs noSQL) is not really the heart of the matter. What is really required is having a database layer that does not enforce a strict explicit schema, but allows an implicit one. With an implicit schema, an Aggregate (as a unit of transactional updates related to an entity) can be persisted and be flexibly updated only when needed.
NoSQL databases (such as MongoDB) are particularly effective in working with implicit schemas, but this strategy can be applied also using relational databases with the help of object mapping features (e.g. DB2 with native XML columns, or Postgres JSON support). I have used this mixed approach to persist and model transportation ticket entities effective, with the ability to choose the most appropriate strategy for each different entity/aggregate.
Versioning Domain Model entities - a cornerstone for architecture evolution
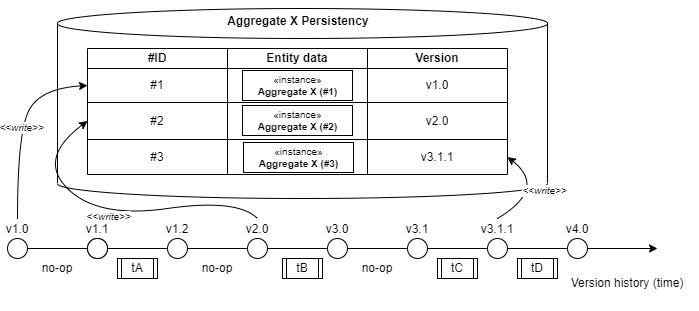
Applying this approach works in two steps, and the first one is the persisting/writing of the entity/aggregate data.
The Domain Model information is serialized using a standard format (e.g XML or JSON) and is always stored with the explicit version being used at the time of writing. Effective implementation of Domain entities serialization using frameworks (e.g JAXB), code-generation, or templating techniques.
Evolving Entities through chaining model transformations
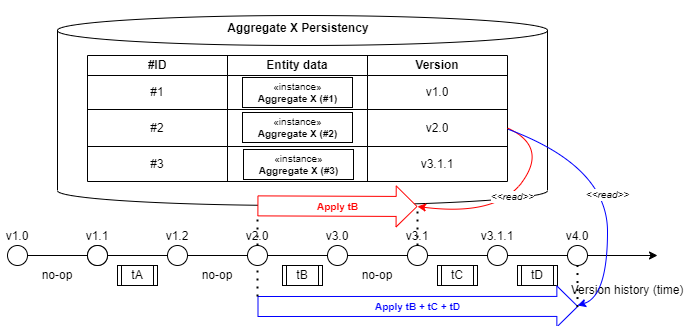
The second step is reading back the persisted entity/aggregate.
After reading the raw data, version of the persisted entity is compared with the current one. If it's the same, good ! Otherwise the system applies a chain of tranformations to progressively update the information up to current version.
Transformations can be implemented in different ways. When persisting in XML format I did found XSLT a natural way to chain XML transformation, but plain code also works.
In the examples presented on the above picture, the aggregate with id #2, originally persisted with Version 2.0, is being read twice:
- The first time, when current aggregate Versio is 3.1, only transformation tB is applied
- The second time, when aggregate Version has increased further to 4.0, thre transformations are chained tB, tC, and tD.
The entity information, now up-to-date, can be deserialized with the same tools used for serializing it.
Key Highlights
Here I focus on some Key Highlights and consequences of adopting this approach.
- On-Demand vs Pre-Emptive evolution
The approach described above updates the entitiy information when reading it, but different trade offs can be applied in chosing when to write it back to database:
- Only if the entity is being explicitely modified
- After reading it
- With a scheduled, pre-emptive updated
Again, in all the scenarios, the entity information will have the updated Version number persisted together with the data.
The third option might be similar to a traditional schema evolution, but with this approach there is no global schema change that might cause outages, allowing each entity record to be updated in background at different times. These updates can be scheduled via batch processes or triggered with database DevOps automation (e.g. Flyway DB updated tasks on relational databases)
- Maintaining transformations
Pre-emptive updates are important also to avoid an increase in the number of transformations to be managed. After having ensured that all the records have reache a certain versio level, the older transformations are no longer required.
- Encapsulation
This is where the DDD approach and encapsulating the transformation logic into the Domain Services did really shine. These services will always provide outside an up-to-date view of data, with a clearly documented API and semantics, published through standards such as Web Services or REST Services through specific API Gateways.
The lack of encapsulation instead quickly becomes an anti-pattern, unless Data published outside of the Bounded Context is documented really well, with clearly defined API and data exchange formats. I did find examples of this antipattern in legacy data models (e.g. of old mainframe applications), with a combination of structured and relational data, evolved over time and lacking a consistent model description. Exposing this data directly to external consumers (e.g. through Copy Banking projects using Change Data Capture - CDC technologies) is then a very risky and complex proposition.
Conclusion
This kind of persistency approach is not applicable in every scenario, but focus on handling application specific data over shared/normalized data models. This make it a good fit for encapsulating persistency in microservices implementation.